Clarit
更好地减少不确定性
如果要力求简单地说明 Clarit 是什么的话,我会只好说它是一个新的笔记应用,和已有的都不一样,它非常灵活和松散,结合了思维导图、网状结构笔记应用、大纲编辑器的优点,同时它是去中心化的,不仅对于个体来说笔记的内容是去中心化的,同时个体也将成为一个去中心化的网络中的一个节点。
可如果要力求准确地解释 Clarit ,我会说 Clarit 是一个能帮助我们更好地减少不确定性的信息系统和一种思维方式,是对如何更好地减少不确定性的一个试探性的回答。它可能不是最好的回答,但它至少重述了这个问题并对之加以讨论。
Clarit 的语义就是澄清、使明确,即减少不确定性。
背景
我们是为了什么而记笔记呢?我想笔记的主要目的应该有且只有一个————帮助我们解答问题。
解答问题的过程实际上是减少回答的不确定性的过程。每一个问题的回答都具有不确定性,我们也可以叫它信息熵,要减少回答的信息熵,我们就需要做功,我们掌握的有效信息越多,我们减熵所需要做的功就越少。我们可以举一个例子来说明这一点,在做一道数学计算题的时候,最初步的回答的熵是较大的,我们需要一步一步演算来减熵,并在这个过程中做功,如果我们被告知了很有效的简化的方法,演算步骤将被缩短,所需做的功也将急剧减少。
由于笔记能够提供信息,而信息可以说是对不确定性的消除(香农的定义),所以记笔记的目的也可以说是为了减少不确定性。
由于环境熵在不断增大,生命需要更强的减熵能力才能在流变中保持自身的存在(同时为了减熵,我们需要更多的信息,因此人们之间的合作会更加紧密,一个人要做成一件事情会越来越需要其他人的协助)。但现在人们的减熵能力相比于二十年前可能并无太大变化,而环境熵却今非昔比,减熵能力的增强落后于环境熵的增长,导致了生命个体的熵增,这可能就是一系列自身存在岌岌可危的问题的肇因(比如抑郁率和自杀率的逐年增长)。
Clarit 试图解答的问题,就是如何增强人们的减熵能力,即是如何更好地减少不确定性。
一个试探性的回答
在将一则信息用于减少不确定性之前,我们需要认识到信息也是具有不确定性的,我们需要先减少信息自身的不确定性(理解信息本身)。所以如果信息的不确定性低(易于理解),则我们理解的代价就越低。
所以为了更好地减少不确定性,我们应该让信息变得明确,易于理解。因此复述和摘抄都是不被推荐的记笔记的方法,因为这些信息并不易于理解。需要注意的是信息熵的大小是对于接受者而言的,同一则信息对于不同时刻的同一个人来说,其信息熵也是不同的。
怎样的信息才易于理解呢?明托在她的《金字塔原理》中说,易于理解的信息都符合金字塔结构。原因是我们在接收信息之后都会自发地把它整理成金字塔结构来理解,所以预先符合金字塔结构的信息,就易于理解。金字塔原理被广泛认为是正确的,但在这里我们还是用信息熵来推导一遍吧。由于我们减少信息的熵的过程,和减少计算题的回答的熵的过程相似,都需要一步一步地减少,而且越是接近结果,熵就越小,因此可以说越是接近最终的理解的信息,就易于理解。对于计算题来说,最终的易于理解的结果应该有着倒金字塔(或者说树)的结构。需要注意的是这里的最终结果指的是完整的演算步骤,不是最后一步,因为没有过程的回答也是难以理解的(或者说是没有信息来减熵的信息的熵很大)。
为什么我们理解的结果是符合金字塔结构的呢?因为每一则信息都要用其他的多则信息来进行解释(减少不确定性),而这些信息是用逻辑关联起来的。比如说“我会死”这则信息不够明确,就可以用“我是人”、“人都会死”这两则信息和演绎逻辑来解释。演绎还是归纳都是从多项关联出一个单项,所以这种逻辑结构就是一个小金字塔。一个小金字塔底部的转头又是另一个小金字塔顶部的砖头,因此最后就是一个大金字塔。
现在来总结一下目前的回答:为了更好地减少不确定性,我们需要获取信息,而且需要减少信息自身的不确定性,减少信息的不确定性的方式是把它预先处理成明确的信息,明确的信息都符合金字塔结构。
但这样的回答还不够,因为减少不确定性的过程,一样是有不确定性的。我们可以用一个例子来说明这一点:现在我们需要从一个使用树状结构的笔记系统中获取到有关“java的语言特性”的信息,这个系统为了减少获取信息的不确定性,事先用归纳逻辑和唯一维度分类原则设计好了层次结构,还使用了杜威十字编码,但现在有几个分类都可能有目标信息,它们分别是“工程实践记录”、“java”、“算法”,其中的记录甚至还不尽相同,如何获取到想要的信息就变成了一个充满不确定性的问题。现在我想把有关“java的语言特性”的信息整理成一成明确的信息,在这样的树状结构的系统中,如何整理起来、整理好了放在哪里、如何处理不一致问题又变得充满不确定性。
所以,为了更好地减少不确定性,我们还需要减少减少不确定性的过程的不确定性。由于这个过程与我们使用的工具息息相关,我们就不可避免地需要设计更好的系统,同时我们还需要改变思维方式。而如何设计更好的系统和如何思考,就是整个问题的难点,也是 Clarit 设计过程中的重点。
我初步认为,好的信息系统应该具有以下特点:
- 完全松散。打破僵化的结构,无论这种结构是树状的文件目录还是树状的文章目录,还是线性的段落,松散信息之间的耦合关系,将信息拆分到最小单元(即一则信息只包含一个逻辑)。
- 重视关联。重视关联而非结构,广泛自然关联的信息将有利于发散和查询,而结构会自然涌现,而最终自然涌现的结构肯定是无法预先设计的去中心化的。
- 去除边界。系统不应该主动限制用户想要获取的信息的边界。
- 单一系统。多个系统如果预先区分,是僵化的,如果未经预先区分,则是混乱的。
- 鼓励输入。提供良好的输入新鲜信息的环境,降低新增信息过程的混乱程度。
- 去除冗余。应该保持简洁,去除不必要的信息。除此之外,还可以允许用户专注于某些信息,或对一些信息进行隐藏。
- 面向集群。由于人们之间的合作会变得更加紧密,减少信息的不确定性,通常需要其他人提供的信息。
以上,就是我的一个试探性的回答。基于这样的回答,我花了两个月的时间编写了 Clarit 。
实现
Clarit 对上述好的信息系统的的六个特点的阶段性的实现:
- 完全松散:Clarit 中没有目录、文件夹、文档、标题的概念,只有节点,节点间有上下左右、引用和被引用的关系。同时每一个节点都是独立的,可以拖动、改变位置、脱离出当前的位置。
- 重视关联:没有结构,只有关联,而且总是会看到关联,工作区间显示的一直是由关系连接起来的连通图。需要注意的是一些节点可能会被隐藏起来(比如外层节点被折叠),将改变连通图的结构,所以连通图的复杂度可以控制在可用的范围内。
- 去除边界:在 Clarit 中的节点,无论关系路径有多远,都可以同时出现。
- 单一系统:Clarit 是去中心化的,即是可以多中心的,所以也可以实现灵活的“分区”。同时这样的单一系统并不会冗杂,因为很多信息都是可以被折叠起来的。
- 鼓励输入:系统其实颇具观赏性,而且由于信息结构松散,可以在任何地方输入,因为整理成本很低,也可以很快找到恰当的地方来输入。
- 去除冗余:整体页面十分简洁,而且用户可以通过专注于特定的节点、折叠、隐藏已完成来去除冗余信息。
- 面向集群:目前只提供了分享功能,尚不支持协同编辑。
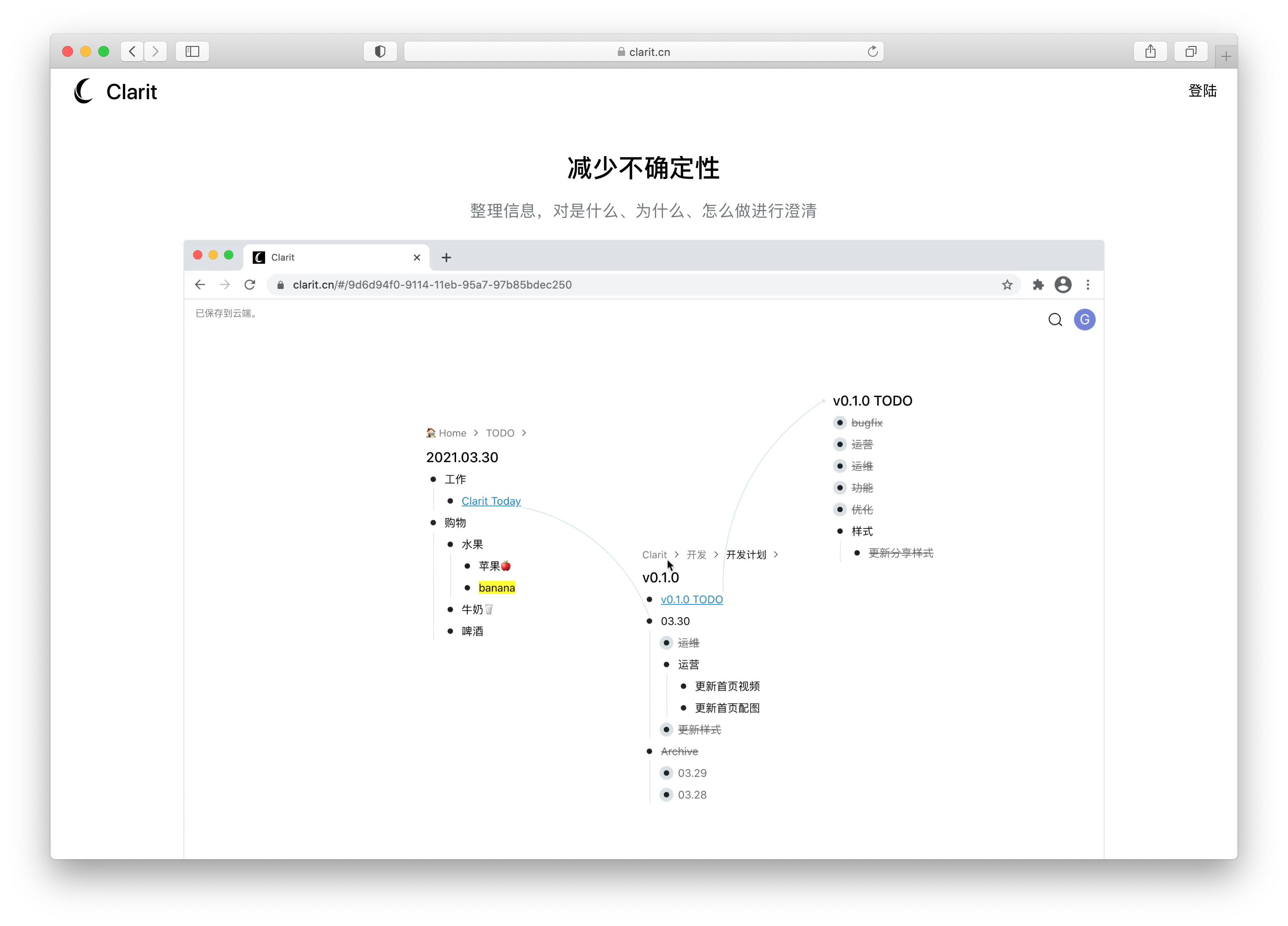
Demo 如下:
关于未来
在未来,信息的组织方式势必会发生改变,由于信息的一些特性,这种改变将会影响深远。 Clarit 在此时此刻只是一个个人的试探性的项目,主要目的是验证和传达一个概念,也希望能激发其他人对这个问题的思考,好让未来更快地到来。
最后,如果您想和 Clarit 一起探寻信息组织的未来的话,欢迎致信 hi@clarit.cn 。